
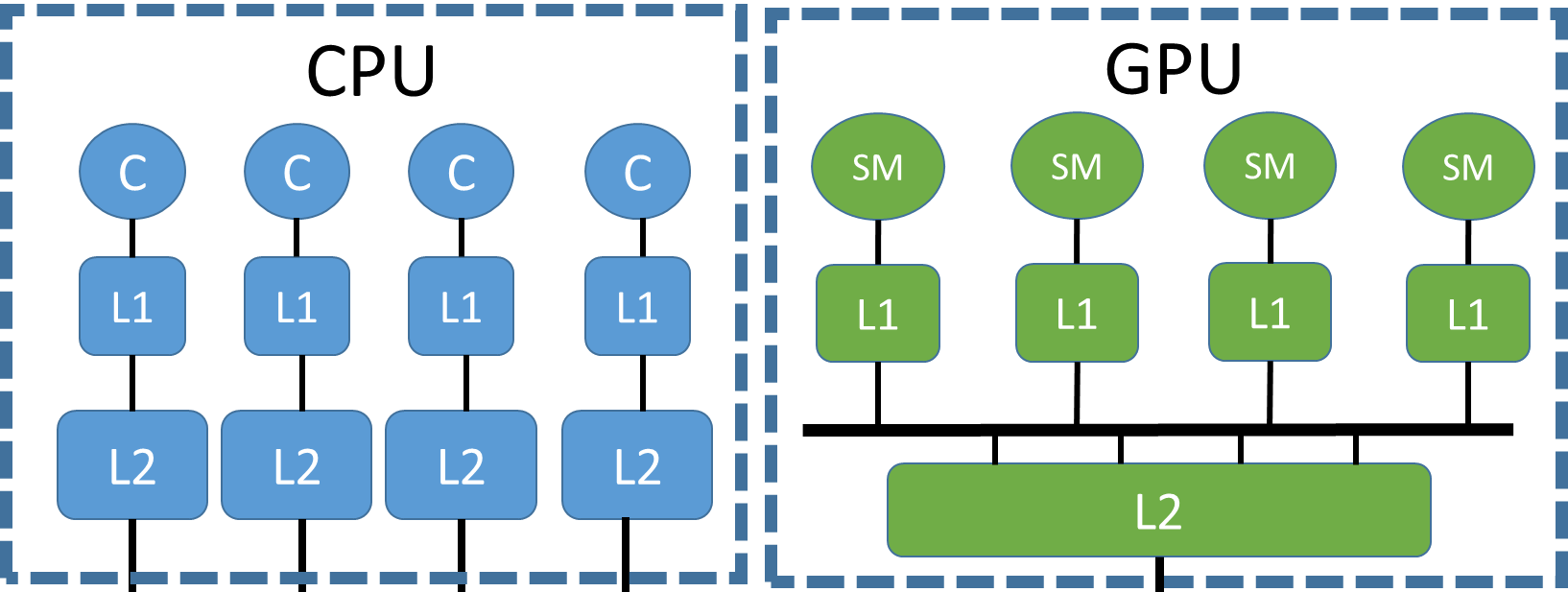
Heterogeneous architectures have become the norm in the field of High Performance Computing. Many of such systems combine Graphics Processing Units (GPUs) and traditional multi-core processors to achieve many Teraflops of computational power.
Summary
GPU programming has traditionally been a cumbersome effort due to the need for explicit data movement between host and device. Vendors like NVIDIA and AMD have acknowledge this problem, and have incrementally provided mechanisms to simplify the task. The first step was to provide a unified view of the virtual memory space to allow pointers to be seamlessly shared between host and device. The latest release of the CUDA programming model goes even further by allowing concurrent access to shared data structures and dynamically performing page migration from the two pools of memory (DDR on host, GDDR on device). Unfortunately, the cost of resolving page faults at the GPU and starting an on-demand page migration is very high, and therefore any programmer attempting to maximize performance is still required to manually manage data movement.